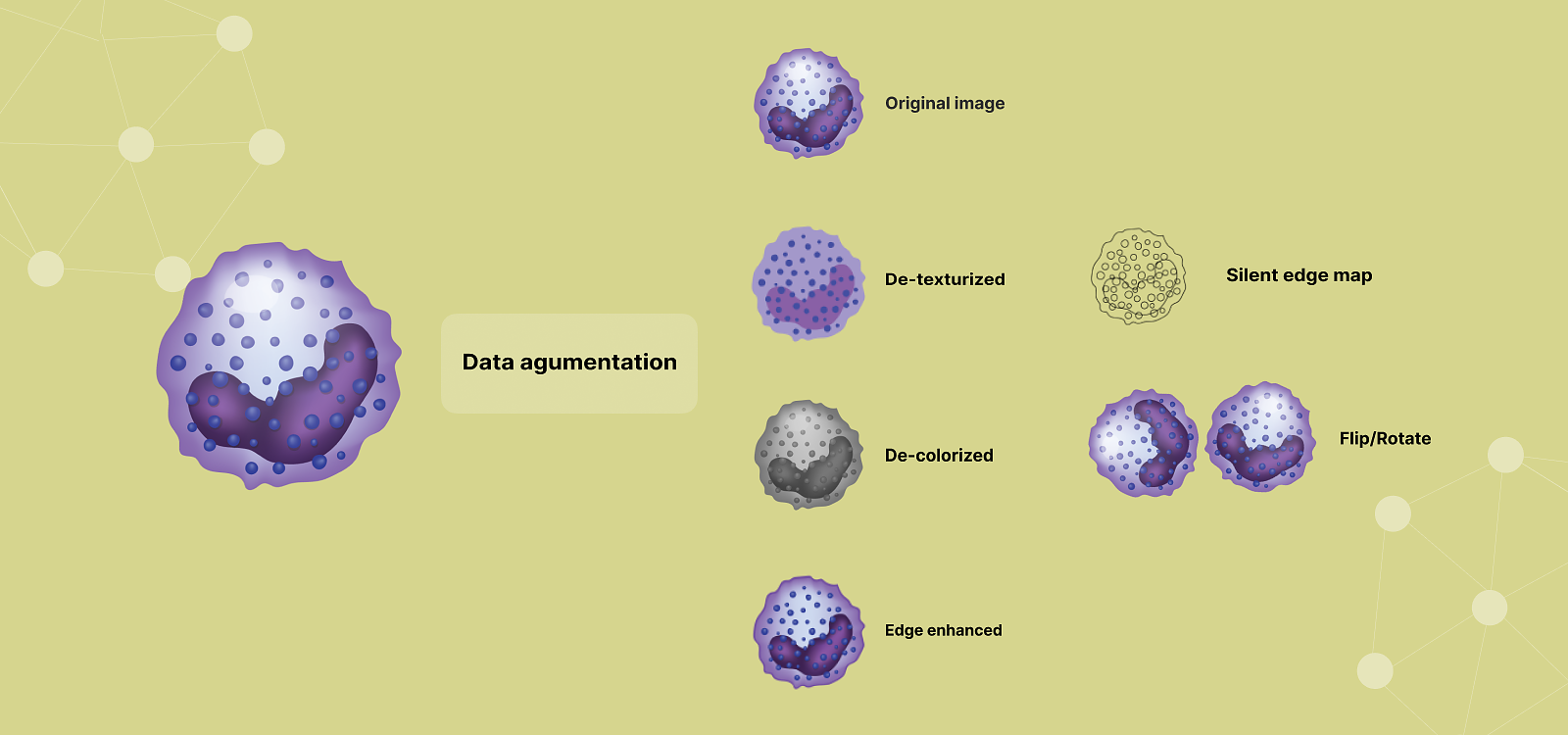

Data augmentation
In previous articles, we looked at how machine learning algorithms use large datasets to produce a model that is capable of mapping a particular input (say, a set of blood parameters or an X-ray image) to some output, for example, a type of a disease or whether a disease is present or not. We emphasized how the quality and quantity of data plays an important role when it comes to the predictive performance of these models. Especially in the field of medicine where the data is of a sensitive nature and sometimes certain diseases are very rare, it might be difficult to collect a large enough dataset to be able to build an adequate model. For this reason, we consider the topic of data augmentation. Data augmentation is the expansion of an existing dataset with synthetically generated examples that are slightly different from the collected data, but which still reflect a real world example. In this article, we will explore some approaches that can be used to generate synthetic data.
One of the most intuitive examples of data augmentation comes from the task of image classification, where the goal of the model is to assign a category to an image. As we already said data augmentation is a technique that allows to generate new examples that are similar to the original data. For the image classification task, we can augment the existing dataset by taking the original images and applying different transformations to them in such a way that the label that the model is trying to predict remains unchanged or is transformed accordingly. For example, if we have images of different blood cells and we want to build a classification model that would be able to differentiate between these types, we could apply transformations such as rotation, mirroring, zooming in, or changing the brightness. The resulting images introduce diversity in the dataset and though they may seem very similar to the human eye they can be very beneficial for the model since these represent totally different examples to the machine learning algorithm.
In the case of blood analysis, the data augmentation might not be so straightforward. But the underlying idea is the same – we would like to increase the amount of data by generating new examples from the existing data. This can be achieved by making small changes to the values of blood parameters. Though this might seem trivial at first glance, we still need to make sure that the changes made still reflect a valid real world case that belongs to the same category (i.e. modified blood parameters would not indicate a different diagnosis). One approach for ensuring the validity of synthetic examples, is by developing a separate binary classification model capable of detecting whether or not an example is an original or a synthetic. Finally, only synthetic examples that the binary classification model was not able to distinguish from the original could be used for training the main classification task.
These are two methods of data augmentation that can be used to expand a machine-learning dataset. In general, the techniques to augment a dataset depend on the type of problem being solved and the kind of data that is available. Irrespective of the techniques used, data augmentation is still a valuable part of developing machine-learning models.



