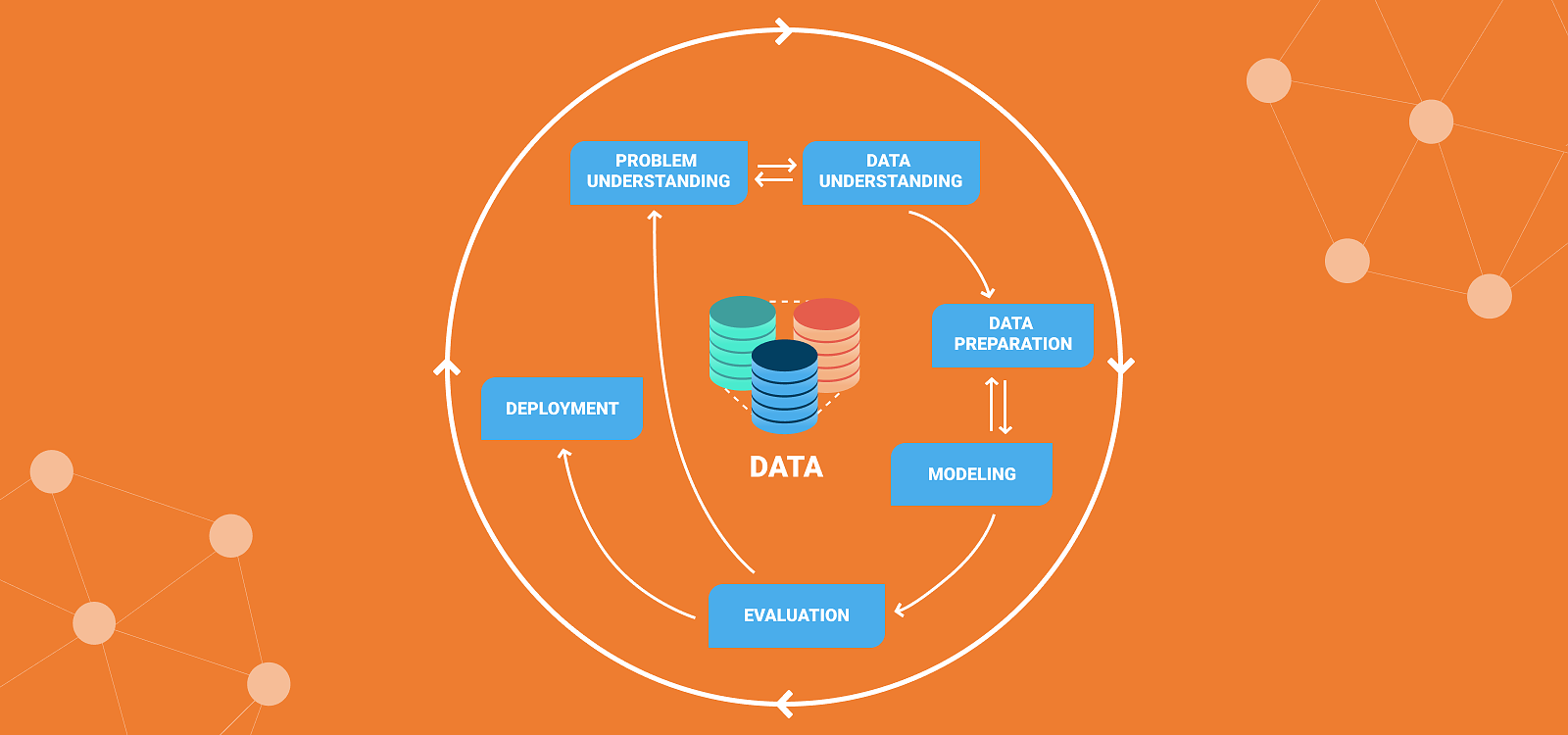

From medical data to an AI-based product
Friends ask me what do I do as a data scientist? I usually simplify things and answer that I search for knowledge in data. Many people think that data scientists just run numerous medical cases through sophisticated machine learning algorithms, and out pops an AI-based product. Well, it is not that simple. The development process for each product includes the following steps:
- Problem (business) understanding
- Data understanding
- Data preparation
- Modelling and Evaluation
- Deployment
Each of these steps is a crucial part of the development process to a useful AI-based product.
Problem understanding
This initial phase of AI product development focuses on defining and understanding the product objectives and requirements. Once we have specified the product from a business perspective, we can formulate it as a data mining problem and develop a preliminary implementation plan. This step is all about asking the right questions. In our case, the question was: “Can we predict the diagnosis based solely on blood test results?”.
An essential part of understanding the problem is determining the end-user and technical evaluation criteria. In our case, we asked ourselves, "How accurate are our predictions?" and "Does our product help the patient to reach the final diagnosis faster?"
Data understanding
Once we have our goals set and we have gathered the data, we need to understand the data. We need to review the availability of data for existing data and also for future data availability and the extent this data can be used for training the AI model. We also need to assess the data quality and detect possible problems with the data.
In the perfect world, we would receive the data in a well-structured and well-documented database. But, in reality, the data is more likely to be a bunch of spreadsheets that we will receive from we receive from laboratories and hospitals. If we are very lucky, there will be some meaningful column headings.
We then need to make a brief evaluation of the suitability of the data for the data-mining goals. For example, we need to verify that the data includes the fields that we need to be there and that there are sufficient cases for analysis. Our typical input data contains blood test results and diagnoses. At this step, expert knowledge is crucial. So, in this step, we rely on the knowledge of expert clinicians who know about the disease, the blood parameters, the working procedures in laboratories and hospitals, and so on. For example, only experts can answer why some patients have more than one diagnosis and why blood parameters differ between genders.
We also need input from an expert to tell us if some values are not valid. For example, it is evident that an Oxygen Saturation of 110 % is an error in data, but what about a Haemoglobin value of 300 g/L?
Data preparation
This step is about executing specific measures for data quality assurance and preparing the data for machine learning. We define which parameters are suitable and which measurements we can use. Expert clinicians then review and approve a list of relevant classes (diseases) and attributes (blood parameters). We then need to encode the diagnoses according to the ICD-10 classification to make them consistent over the entire dataset.
We may have some parameters measured multiple times, and we need to handle these cases adequately and, most importantly, consistently. Another important factor is blood parameter measurement units, which can differ between different hospitals or even laboratories from the same hospital.
We remove some cases from the dataset due to mistakes, strange values, or not fulfilling some of the requirements. For example, we only use the data for patients aged 18 and over and remove cases for pregnant women.
Modelling and evaluation
We use different machine learning methods depending on training data and data modelling to build many models using various algorithms and settings at this step. Each model is evaluated based on the end-user and technical evaluation criteria defined in the first step. We select the best overall models for the deployment.
In the real world, we are usually not satisfied with the results in the first iteration. We repeat these steps until we get the results that coincide with our business goals. The critical part here is a well-designed evaluation so that the models will be equally effective in practice.
Deployment
And finally, we have a predictive model! But the work does not end there. Now we need to make it available to our users. Of course, only having a good AI model is not enough for a good product. From the manufacturer perspective, security is fundamental, so the models can't be compromised. From the user perspective, there needs to be a good UI/UX, so the product is easy to use and understand. And last but not least, a product must be CE certified before it can be put on the market. The result of all these efforts could be a great product, like mySmartBlood.



